TeLeS scores confidence in ASR with word/time similarity, making speech AI more reliable and self-aware.

TeLeS scores confidence in ASR with word/time similarity, making speech AI more reliable and self-aware.
A new model learns audio embeddings and balanced hash codes together — enabling faster, noise-resistant audio search.
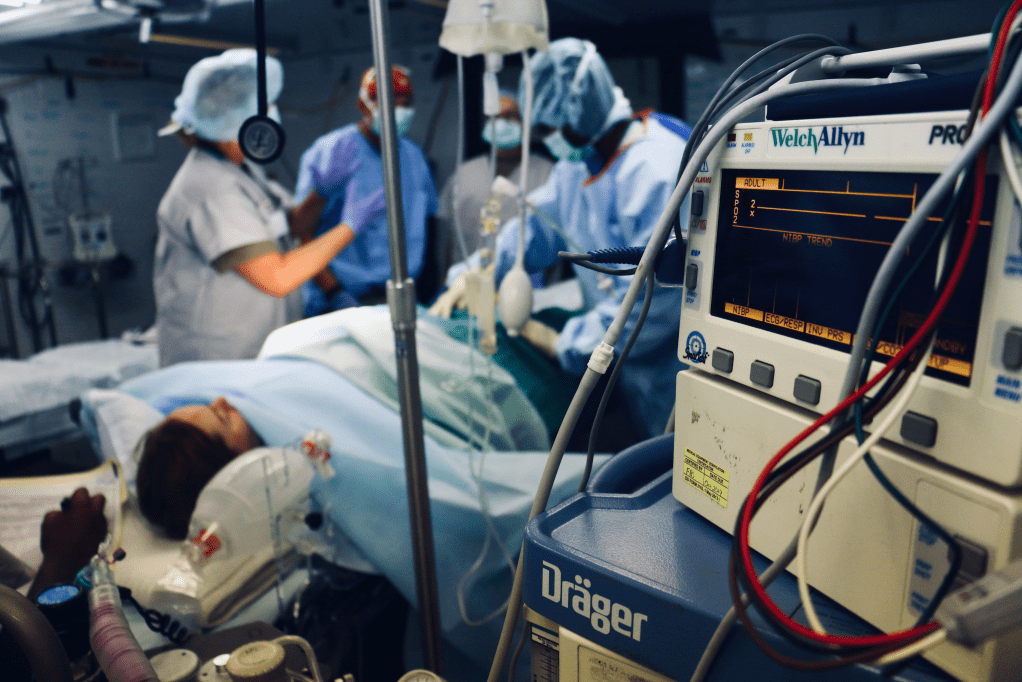
A domain-specific Hindi dataset helps voice models assist nurses during childbirth in noisy Indian hospital settings.
A TF-IDF powered audio search method turns speech into tokens — making spoken queries faster and language-agnostic.
AudioNet uses deep hashing to create smart sound fingerprints for faster, high-precision retrieval of similar audio clips.

Balanced Deep CCA learns from audio and body vibrations to detect bird sounds without tons of labeled data.

An RNN learns fixed-length audio embeddings from speech — enabling ultra-fast word search without any text labels.

An interactive learning model adapts to new music genres with just a few annotated samples from users.

This model learns with ontology constraints, detecting audio events more accurately while respecting real-world sound hierarchies.